The Data Infrastructure Layer Is Being Rebuilt — Is the Insights Industry Sleeping Through It?
A new supply ecosystem is forming around verified human data. The question is who owns it.

Note: We are experimenting with various ways to make our content more engaging and impactful using AI tools like Notebook LM. You’ll notice a variety of graphics in this report, but we also have adapted the content to a video as a “tldr” option. Let us know what you think of both?
Here is the video summary of the post first.
Something structural is happening underneath the surface of the insights and analytics industry, and most participants are not yet treating it as what it is.
The demand for verified, permissioned, refreshable human data has moved from a nice-to-have to the foundational input of the AI economy. Large language models need it to train. AI agents need it to operate. Enterprise decision systems need it to calibrate. And the businesses that can supply it reliably — at API cadence, with documented provenance, at scale — are being repriced by the market as something categorically different from research vendors.
They are being priced as infrastructure.
That transition is happening whether the insights industry participates or not. And a growing number of companies outside the traditional MR universe are positioning to capture it.
The demand is real. The supply is being rebuilt.
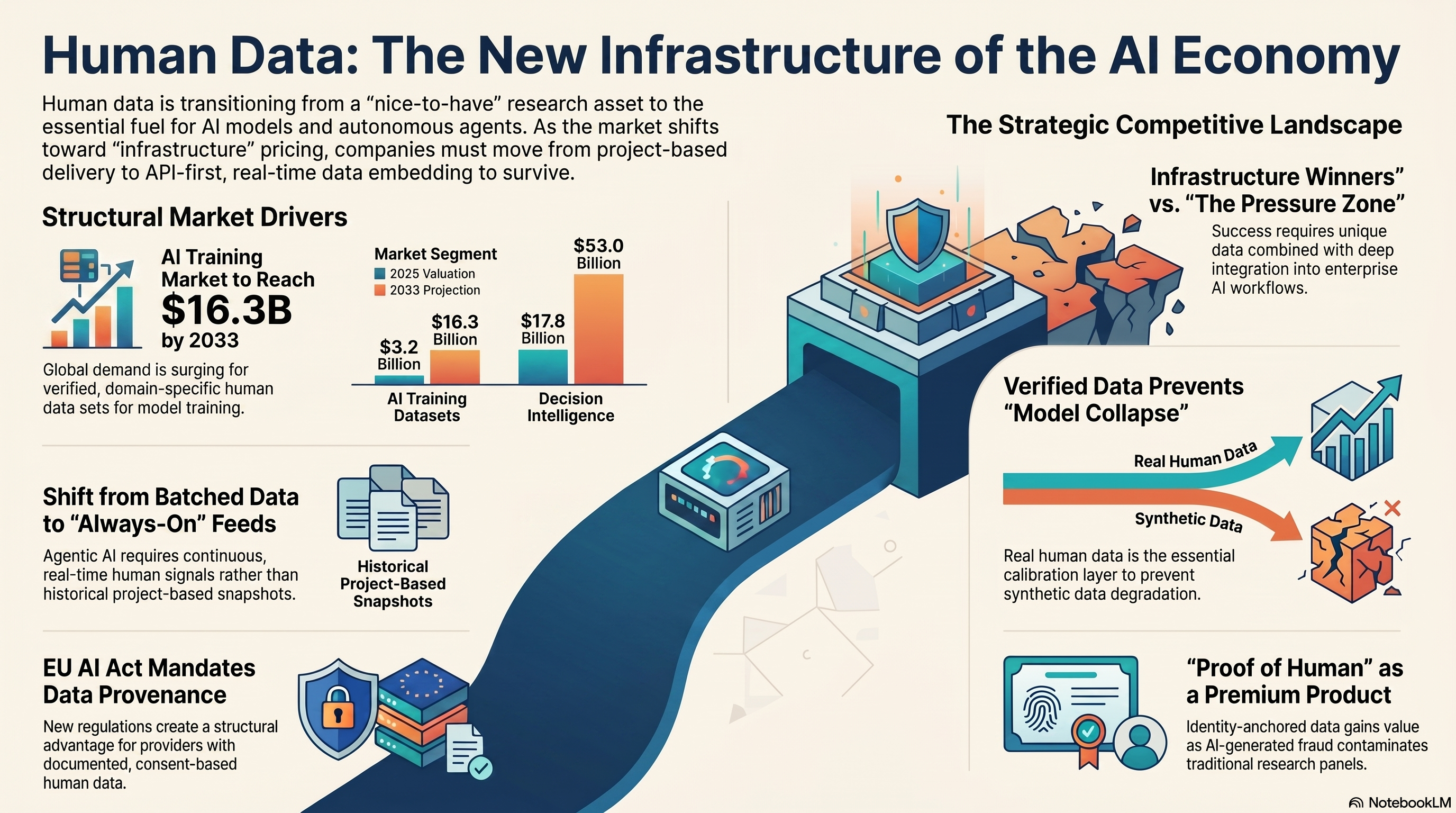
AI model development is not just about compute. The limiting factor for the next generation of models, agents, and AI-native enterprise systems is high-quality, verified, domain-specific human data. The global AI training dataset market was valued at approximately $3.2 billion in 2025 and is projected to reach $16.3 billion by 2033. The decision intelligence market — the downstream layer where human data feeds enterprise AI systems — was $17.8 billion in 2025 and is on track to reach $53 billion by 2033.
Those numbers describe the market that is forming around the kind of data the insights industry has been collecting for decades.
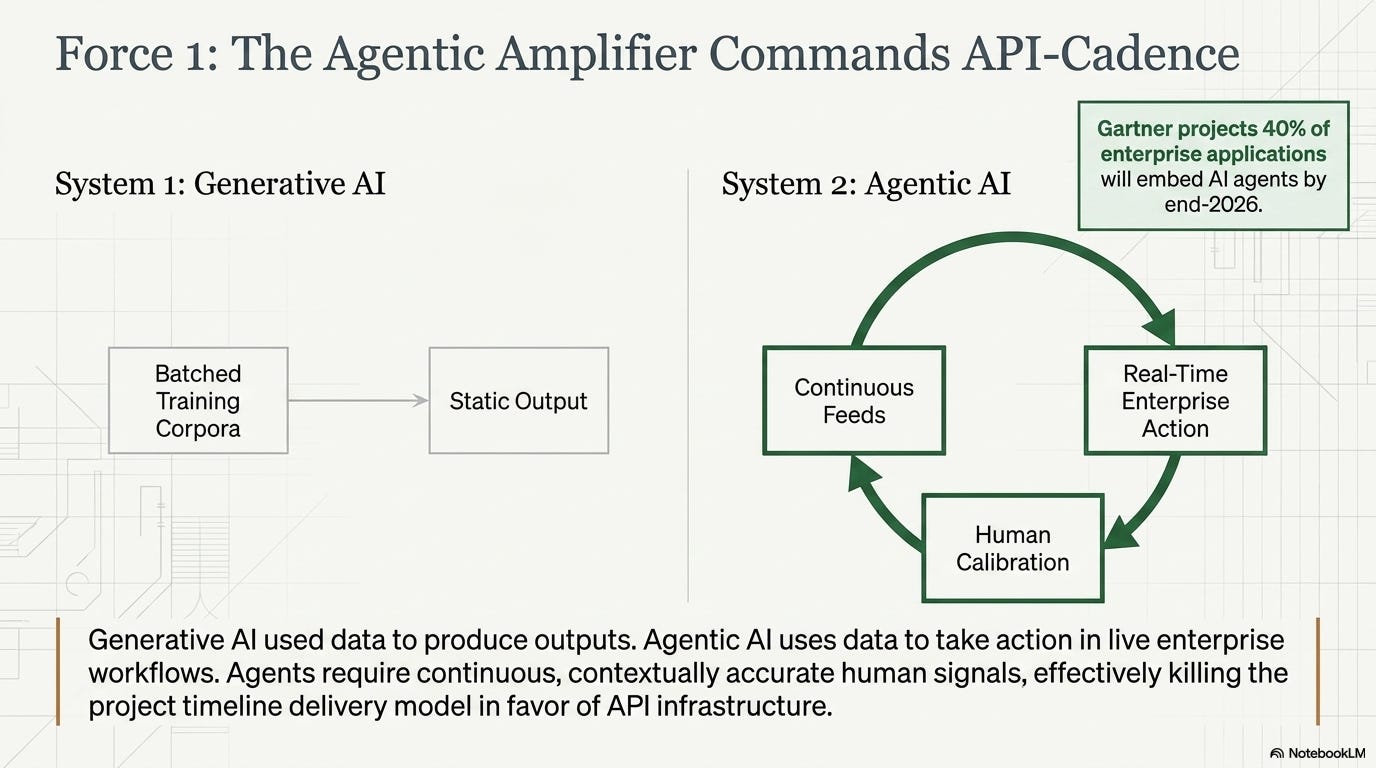
The structural demand driver is the transition to agentic AI. Generative AI used data to produce outputs. Agentic AI uses data to make decisions, take actions, and adapt in real time. Gartner projects that 40% of enterprise applications will embed AI agents by end-2026. Agents that operate on the internet, inside enterprise workflows, and across consumer touchpoints need continuous, contextually accurate, trustworthy human signals — not just a batch training corpus they were initialized on. That is a fundamentally different data demand than what built the current AI ecosystem, and it is not being satisfied by synthetic data or web scraping alone.
The insights industry invented the supply chain for verified human data. The question is whether it rebuilds itself as the infrastructure layer for the AI era or watches that position get claimed from outside.
A new class of infrastructure players is forming
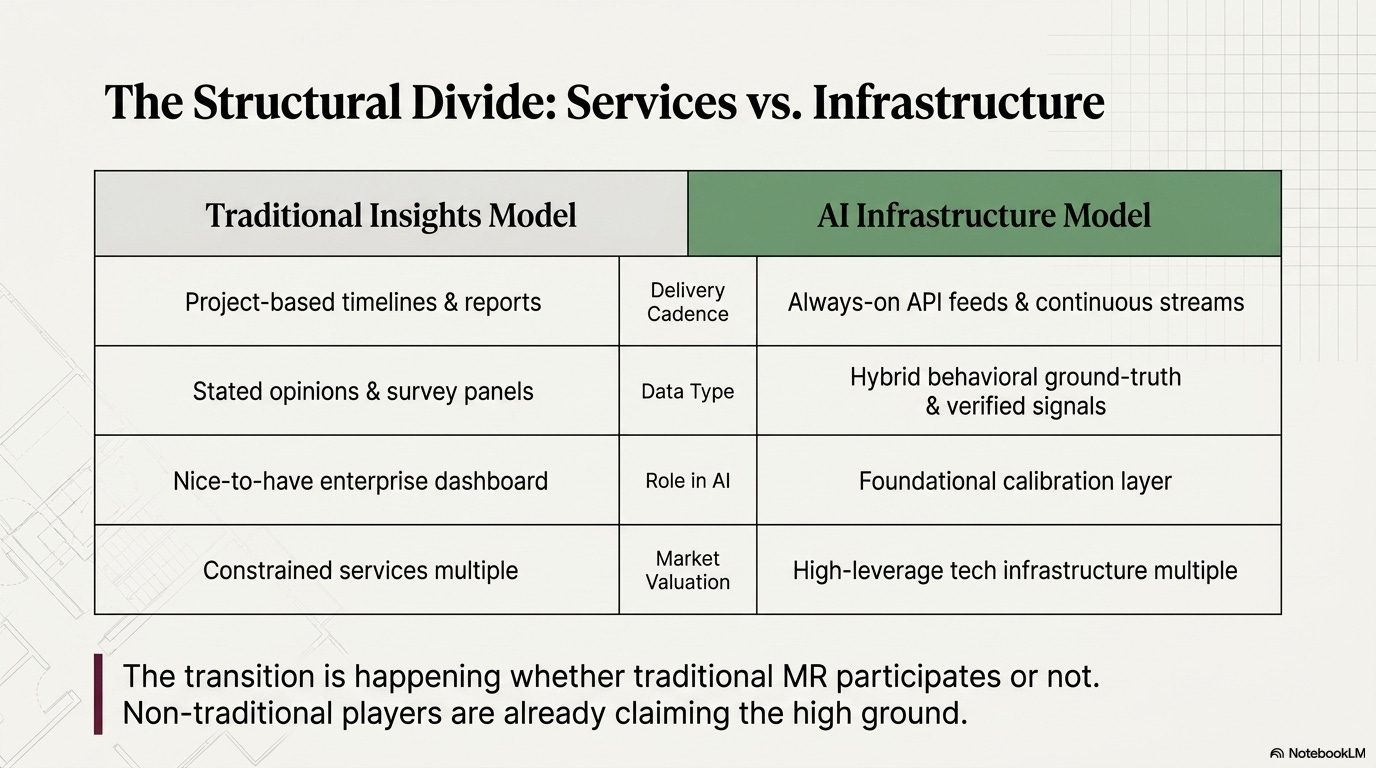
The competitive landscape around human data has fractured into a set of supply categories that barely existed five years ago, and the traditional research industry occupies only one of them.
Note: We’re going to mention a few companies as we dive into this as examples in each category: this is just a representative sampling of players, not a census and no offense is meant to any supplier if you were not mentioned, and no implied endorsement is meant for any we do.
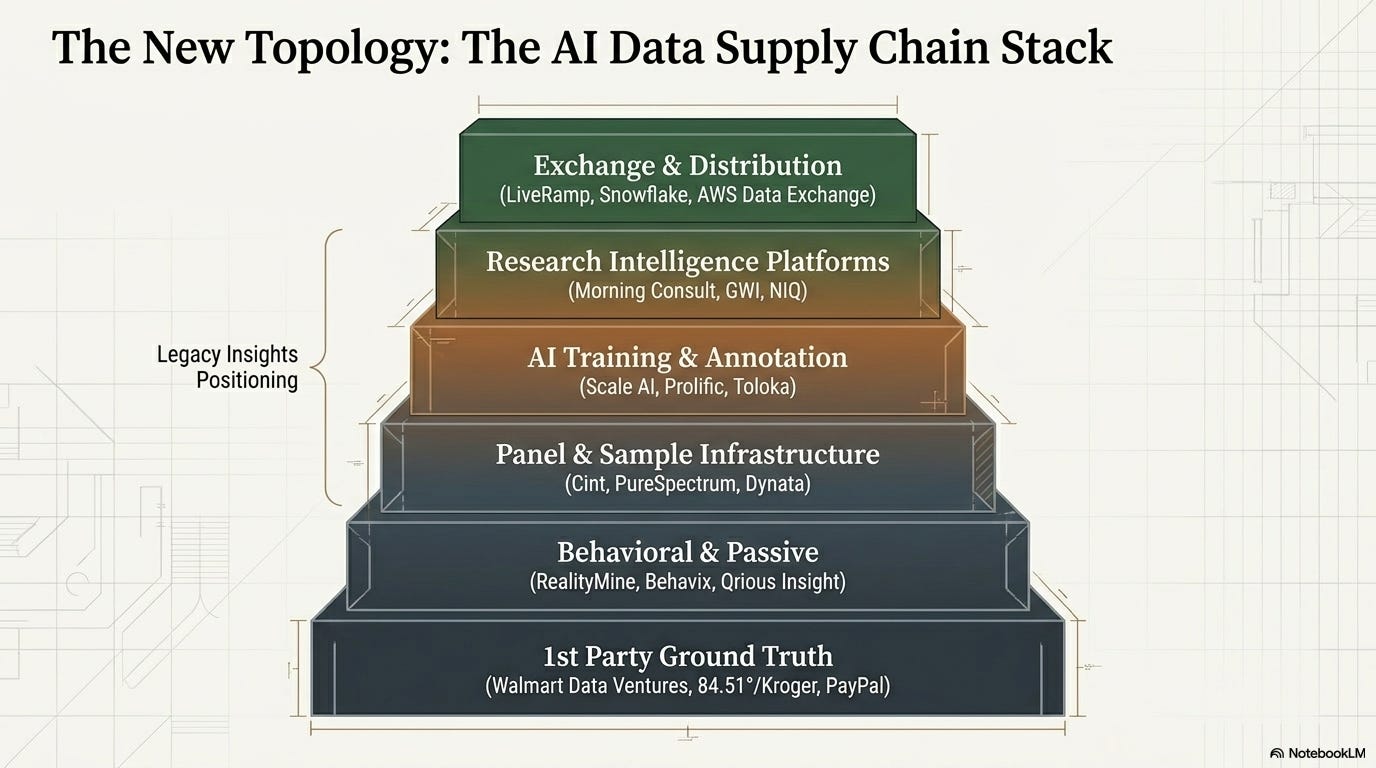
Dedicated AI training and annotation platforms — Scale AI, Prolific, Toloka/Tendem, Appen, TELUS Digital, Defined.ai, Surge AI, Pareto.ai, Clickworker, Turing.com, Mechanical Turk — have built explicit infrastructure positioning around human data for model training, RLHF, evaluation, and red-teaming. Scale AI’s 49% acquisition by Meta for over $14 billion is the clearest possible capital markets signal about what the AI ecosystem is actually willing to pay for verified human data infrastructure. Prolific — which brands itself as “a unified infrastructure to design, launch, and manage human data workflows at frontier speeds” — is approaching $350 million in annualized revenue while serving over 35,000 AI developers. These are not survey companies that added AI features. They were built for this moment.
Panel and sample infrastructure companies — Cint Exchange, PureSpectrum, Sago, Dynata, Prodege, Pureprofile — occupy a more familiar category but are at different stages of transition. Some, like PureSpectrum, have launched explicit AI training data products and synthetic-real hybrid pipelines. Others are in the project-services category with unclear infrastructure trajectories. The distinction between a panel company that has repositioned as AI data infrastructure and one that has not is becoming a valuation-relevant distinction.
Behavioral and passive data providers — RealityMine, Qrious Insight, Behavix, Numerator, Mode Mobile — supply observed rather than stated behavioral data: passive digital metering, omnichannel device tracking, purchase behavior, real-time interaction signals. The AI relevance is high because behavioral data provides ground truth that survey data cannot: what people actually do rather than what they say. Qrious Insight’s explicit positioning as “Ground Truth Data For AI” reflects an emerging category of companies building behavioral data infrastructure explicitly for AI use cases. Many of these companies are selling behavioral SDK infrastructure directly into panel companies — enabling legacy panel businesses to become behavioral data nodes rather than sample-access points alone.
Research intelligence platforms — Morning Consult, GWI, YouGov, Futurum/ETR — are established research businesses that have declared explicit moves toward decision intelligence and data infrastructure positioning. Morning Consult’s 112% SaaS growth on the back of always-on daily survey data packaged as an agentic decision platform is the clearest proof point that research intelligence, repackaged as subscription infrastructure, can command technology-style economics. GWI’s positioning that “AI Is Only As Good As Its Data” and its synthetic audiences built on real human survey data represent concrete product execution on the hybrid model.
Retailer, financial services, and platform first-party data providers — Walmart Data Ventures/Scintilla, 84.51°/Kroger, Actual Platform, PayPal Ads, Chase Media Solutions, Visa Intelligent Commerce, CVS Health/ExtraCare — represent the most consequential structural development in the landscape, and the one the insights industry is least prepared for. These companies did not enter the intelligence business through research. They arrived through commercial relationships at consumer scale. Walmart’s Scintilla platform provides API-accessible first-party behavioral data across approximately 500 operational and retail data elements. 84.51°/Kroger holds purchase behavior data from approximately 60 million US households. PayPal analyzes “nearly half a trillion dollars of transaction data with artificial intelligence”. No research panel can replicate those behavioral data assets. The question the insights industry has to answer is not how to compete with them on transactional behavioral ground truth — it cannot — but how to occupy the intelligence layer they structurally cannot provide.
Data marketplaces and exchange infrastructure — LiveRamp, Snowflake Data Marketplace, AWS Data Exchange — are becoming the neutral distribution layer through which data assets reach AI consumers. LiveRamp’s January 2026 expansion to support AI training data licensing is significant: it positions LiveRamp as the exchange infrastructure through which any data asset — panel data, behavioral data, purchase data — reaches enterprise AI buyers and model developers. Distribution through these channels is becoming as strategically important as the data asset itself.
The structural forces that are reshaping the category
Four dynamics are converging to accelerate this transition. Understanding them is more useful than tracking any individual company.
The agentic amplifier. The shift from generative to agentic AI is not incremental. Agents that take actions, make decisions, and adapt to outcomes in live enterprise workflows require continuous, real-time, contextually accurate human signals — not just historical training data. The demand is moving from batched corpora to always-on feeds. Companies that can deliver human data at API cadence will occupy a structurally different position than companies that deliver research deliverables on project timelines. This is the demand inflection that separates data infrastructure from data services.
The regulatory moat. The EU AI Act is fully applicable from August 2, 2026. Article 10 mandates that training data for high-risk AI systems be “relevant, sufficiently representative, accurate, consistent, and to the best extent possible free of errors and complete”, with documented provenance, source categorization, and bias assessment. This converts consent documentation, representativeness, and data provenance from best practices into legal requirements. Providers that have always operated with opt-in, consent-documented data collection — and can demonstrate it — have a structural compliance advantage over web-scraped datasets, synthetic data, and commodity crowdsourcing. The EU AI Act is, effectively, a regulatory moat for premium human data infrastructure.
The synthetic-real convergence. Synthetic data has real value in specific applications: rapid prototyping, messaging pre-testing, scenario modeling, privacy-sensitive research, augmenting underrepresented segments. Gartner projects it will surpass real-world data in AI training volume by 2030. But volume is not primacy. The research evidence is increasingly clear that AI systems trained exclusively on synthetic data risk progressive performance degradation — what researchers call “model collapse” — as recursive training on AI-generated output drifts from human reality. The emerging standard is a hybrid model: synthetic data for scale and speed; verified real human data as the calibration foundation that prevents drift and satisfies regulatory requirements. This model creates demand for premium human data assets rather than destroying it. The insight industry’s job is to be the calibration layer, not to compete on synthetic volume.
The fraud premium. The infiltration of AI-generated synthetic participants into online research panels is an acute and accelerating threat to data quality. As AI-generated ghost respondents proliferate in commodity panels, the value of demonstrably human, verified, identity-anchored data widens. The insight industry has spent decades building quality controls for exactly this problem — sampling, bias detection, fraud signals, respondent validation, methodological rigor. That expertise is becoming a premium product feature in an era of synthetic contamination, not a back-office process. Companies that convert their quality infrastructure into an explicit, front-facing competitive asset — “proof of human” as a product — will compound that advantage as the panel fraud problem worsens.
The market has sorted into four strategic positions
Plot the emerging competitive landscape on two axes — data uniqueness and irreplaceability (vertical) against infrastructure integration depth (horizontal) — and the field resolves into four positions.
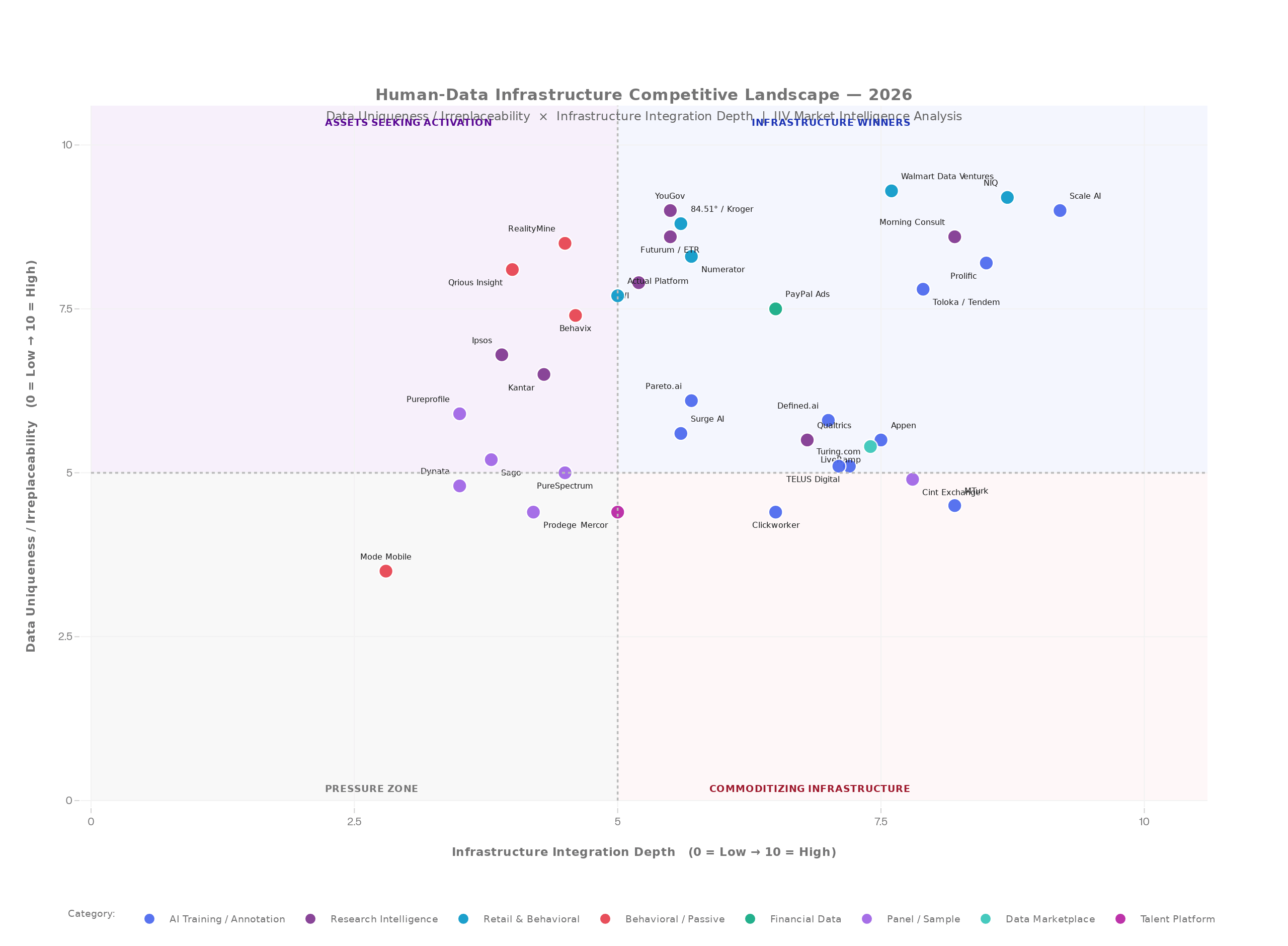
Infrastructure Winners occupy the top right: companies with genuinely unique or difficult-to-replicate data that have also achieved deep embedding in AI and enterprise workflows. Scale AI, Prolific, NIQ, Morning Consult, Toloka/Tendem, Walmart Data Ventures are in this zone. They are being contracted as infrastructure, not projects.
Assets Seeking Activation occupy the top left: companies with genuinely differentiated or irreplaceable data that have not yet achieved full workflow embedding. This is where most of the insights industry’s established players sit, alongside the most interesting new behavioral and first-party data entrants. The data is right. The distribution and embedding are not yet complete. This is the zone with the highest near-term strategic stakes.
Commoditizing Infrastructure occupies the bottom right: companies with high operational embedding in AI workflows but undifferentiated data. Margin pressure here is structural. The path out is either specialization (move up the uniqueness axis) or cost leadership (move down-market).
The Pressure Zone occupies the bottom left: lower differentiation, lower embedding. This is where the most existential risk concentrates. Without a significant strategic move — in either direction — companies here face progressive compression as better-positioned alternatives absorb their clients’ budgets.
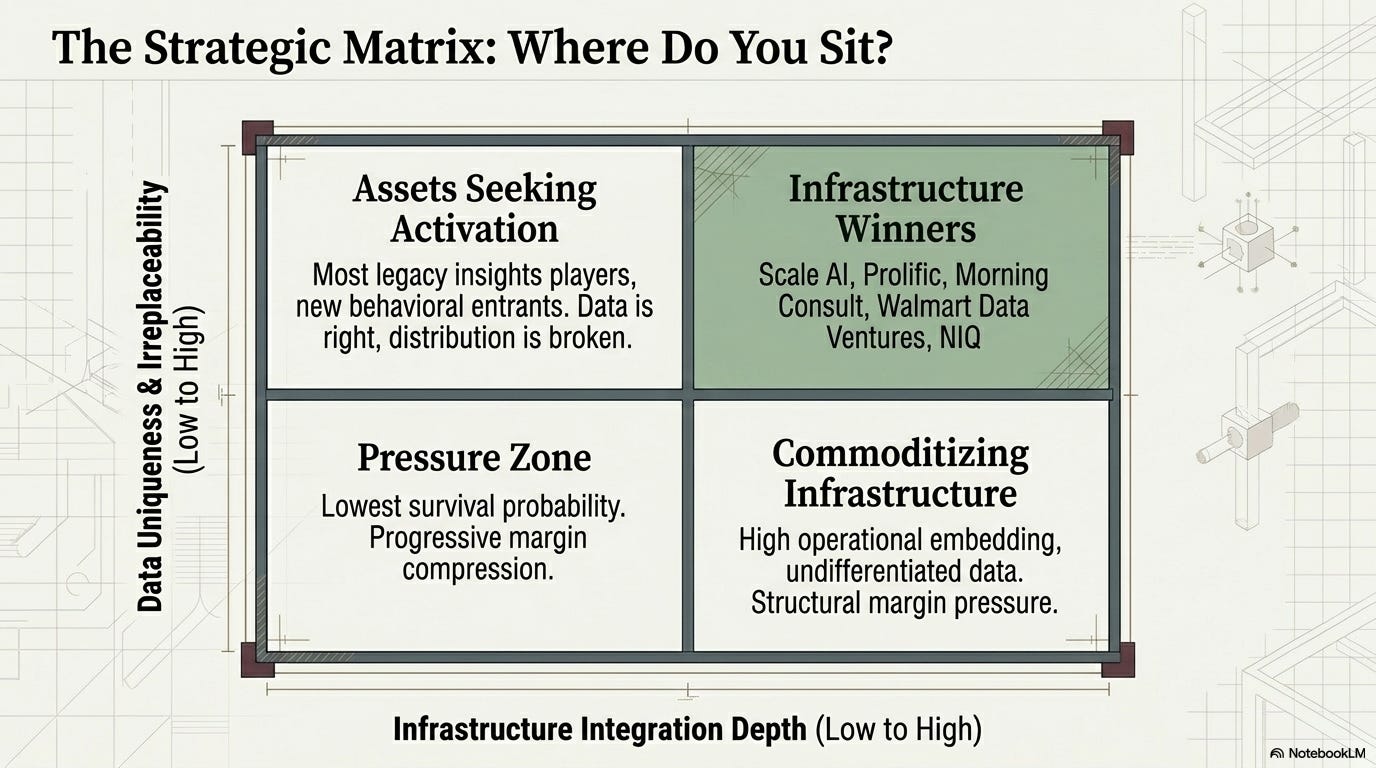
The most important strategic observation: the distance between “Assets Seeking Activation” and “Infrastructure Winners” is not a data problem. The data is often already there. It is a distribution, embedding, and developer-accessibility problem. The companies that close that gap first — through marketplace listing, API-first interfaces, enterprise workflow integration, and LiveRamp-style licensing infrastructure — will be the ones that convert existing data assets into infrastructure-level economics.
The real threat is not replacement. It is abstraction.
The most dangerous scenario for the insights industry is not that AI replaces research. The more likely danger is that the industry gets abstracted — layer by layer, workflow by workflow — until traditional research suppliers become less visible in the decisions that matter.
The client’s enterprise AI platform absorbs the dashboard. The synthetic data tool absorbs early-stage concept testing. The CRM absorbs customer understanding. The product analytics platform absorbs user research. The sample marketplace abstracts respondent access. The AI agent abstracts the analyst.
None of those substitutions happen all at once. But each one makes a traditional research supplier marginally less essential to the client’s decision workflow. Abstractions compound.
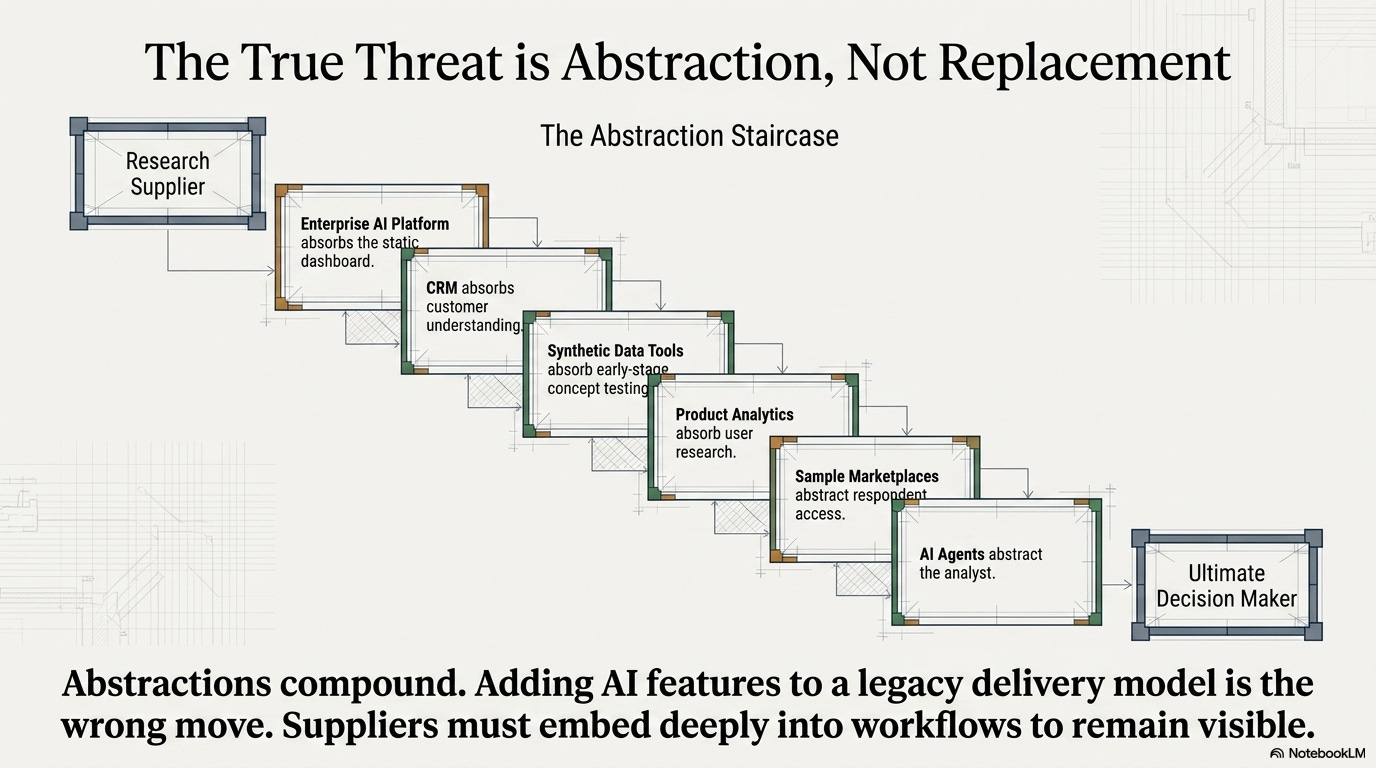
The response is not to add AI features to the existing delivery model. That is the wrong move, and the insights industry is already making it at scale. The response is to move closer to where decisions are being made — to embed into workflows, own trusted data that cannot be synthesized, provide governance that AI systems need and cannot self-supply, and deliver judgment that connects the signal to the action.
The companies building human-data infrastructure are not doing this because AI is interesting. They are doing it because the architecture of enterprise decision-making is being rebuilt, and the firms that sit inside that architecture at the infrastructure layer will be structurally embedded in ways that project-based suppliers cannot match.
The insights industry has the raw material. It has the consent architecture, the panel depth, the methodological rigor, the behavioral fusion capability, and the interpretive expertise that no transactional data asset and no AI model can independently replicate. The firm that combines verified opinion, behavioral fusion, and developer-accessible infrastructure at global scale with documented provenance will define the category for the next decade.
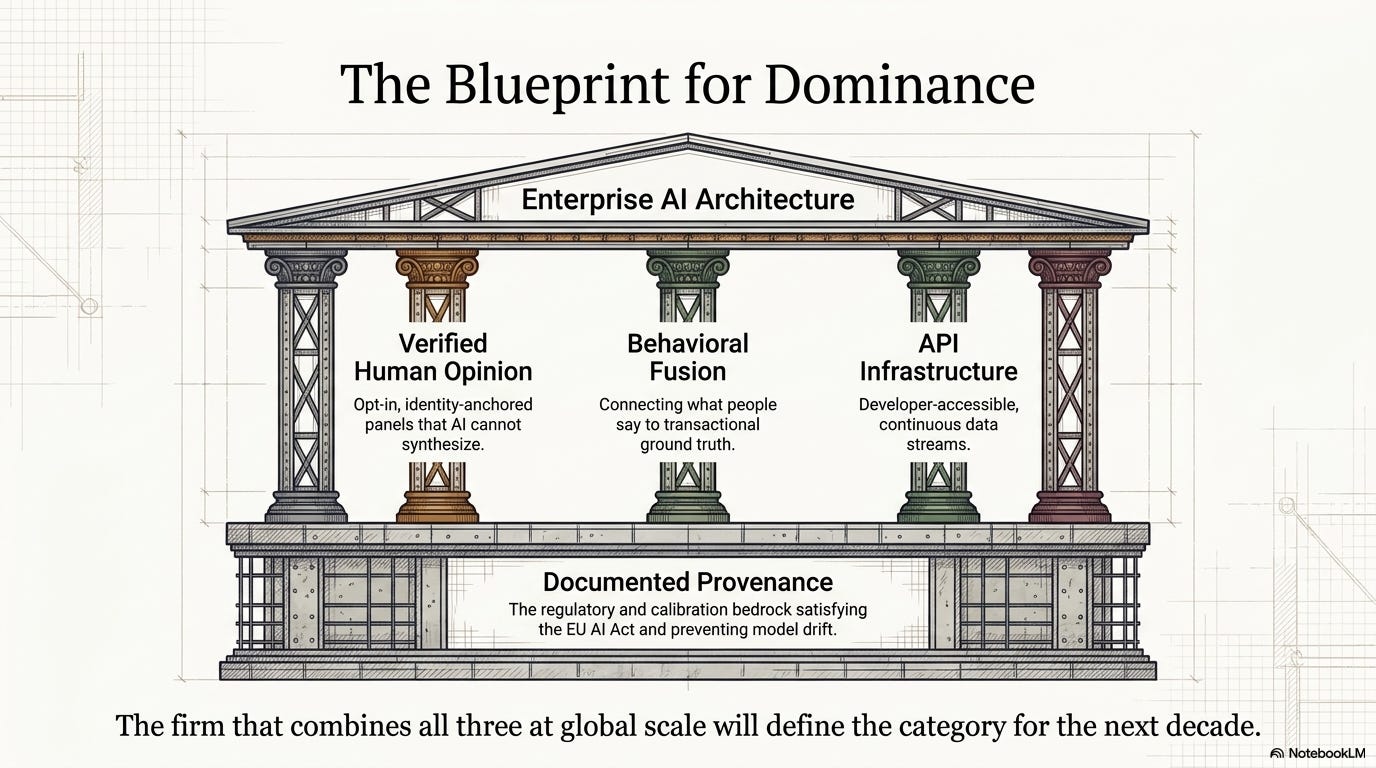
That firm could come from inside the insights industry or from outside it.
The window is open. It is not open indefinitely.
Insight Innovation Ventures invests in AI and analytics startups across the USA and UK, with a focus on data infrastructure, research technology, and AI-native insight platforms. This post is part of an ongoing series on the structural transformation of the insights and analytics industry.
Great insights here. The only thing I’m not sure about is whether AI Data Supply Chain Stack is meant to be a path from the bottom to the top or just a list. Because if you have the data, it seems you could go straight to LiveRamp distribution and not route through a Research Intelligence Platform.
Also, currently, companies in the legacy insights bucket are generally not putting a premium on human verified data, but maybe their hands will be forced if AI eval work raises demand and price for good data. Like, why bother supporting survey projects that pay pennies? It’s amazing to me that legacy companies don’t seem to get this.